SWE-bench: LLM Developer Metrics vs. Hype

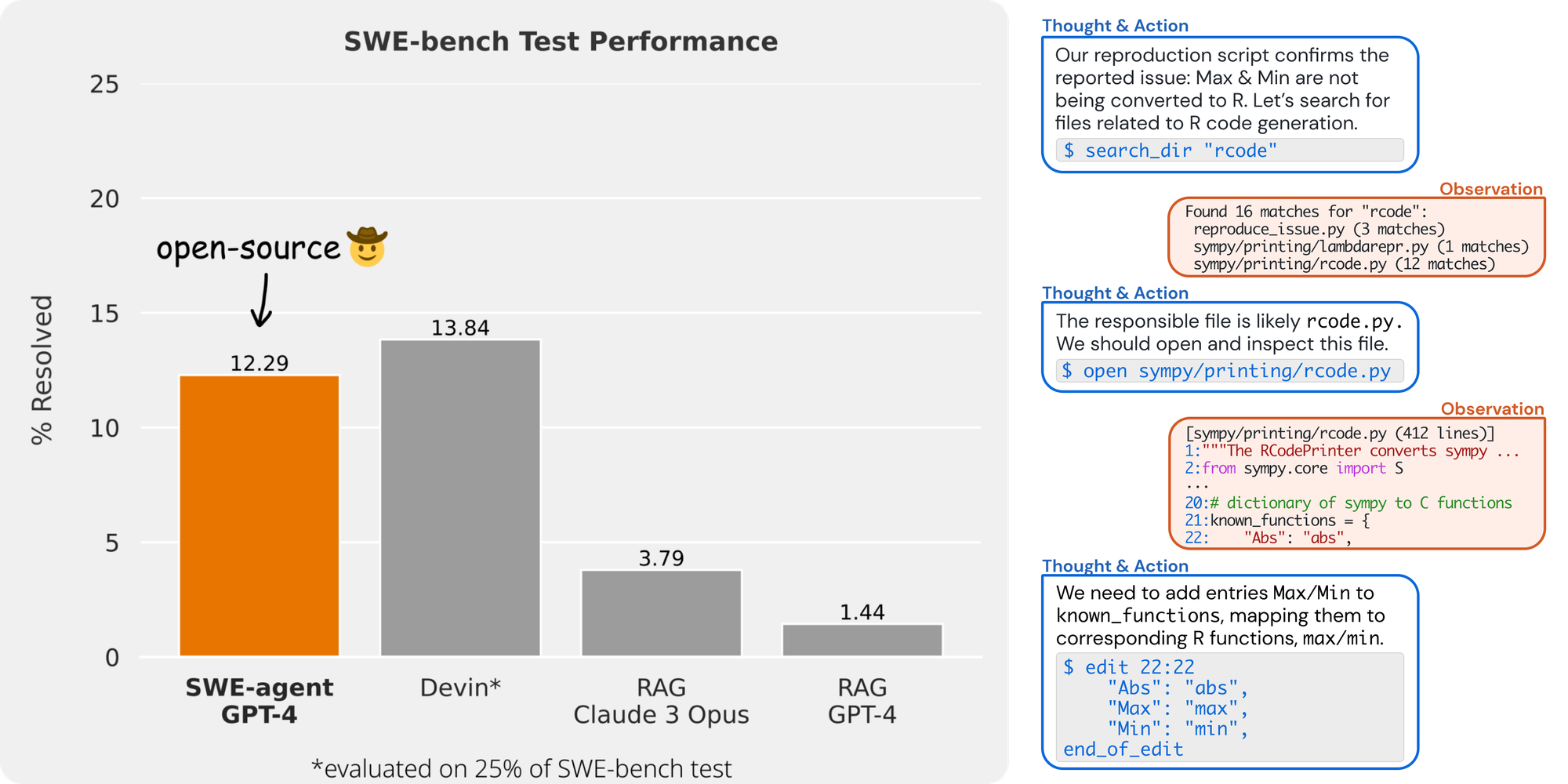
TL/DR; SWE-bench evaluates current LLMs abilities to complete common developer tasks and shows that, even with task specific agents, today's LLMs are at best ~12.5% successful. We need more benchmarks like these.
Real-world benchmarks like these are critical for engineering leaders to understand so we can make better decisions. They help bracket what a tool, technique, etc. is good for. They don't show what a given approach might do some day, they show what it can do today. We need metrics like these to objectively evaluate products and techniques so we can make informed decisions about which to adopt and how to best utilize them.
(Note: Devin does slightly better but I'd compare SWE-agent benchmarks vs Devin rather than the raw LLM numbers they cite. The difference is about 1% vs. open source)
I'm not an AI specialist or researcher. I am an end consumer of these tools and offerings and need to think about what I'd recommend my employer spend budget on and how I'm going to make that investment as effective as possible. I'd wager that most folks fall in this category. These benchmarks hold immense value for training new generations of models but this posts isn't about that.
There is snake-oil everywhere, always has been, and probably always will. This isn't unique to Machine Learning or whichever trending technology of your choice. There is also a lot of "unintentional" snake-oil. Decent products, languages, tools, etc. shoe-horned into the wrong use cases. It could be because of overselling capabilities, an uniformed mandate, magical thinking, etc..
Having well understood, impartial, and repeatable metrics are a key part of being able to compare products and methodologies. If you're signing the check, you own the results. I'd argue it's not the vendor and certainly not a consultancy you brought in to help out.
If you're selling me an LLM to automate developer tasks at a 13% success rate I'm not going to use a tool for that purpose.
For the record I AM NOT SAYING THESE TOOLS ARE SNAKE OIL. I'm not saying that they are uninteresting or a fad. I am saying that you can't use a tool that doesn't exist and you shouldn't use a tool that you can't objectively evaluate. As a spectator, techno-nerd, and potential customer, I'm deeply interested. It's wild what has been accomplished. As a pragmatist, I can't use it today and I want a lot more data.
In my opinion we should think about what these tools do well and how you can use them – just like anything else in your toolchain.. For example, Thoughtworks has some good pointers on using RAG to work on a legacy codebase. That's potentially a great way to put more tools in the toolbox for engineers, especially for those "island of the misfit toys" repositories that companies always seem to accumulate. I'd love to see more data on how effective the technique is.
I have found Github Copilot so useful in development tasks and I pay for my own subscription for side projects. Copilot does make erroneous assumptions and generates garbage code on occasion but I'm fine with that because I'm using more like an integrated search and drafting tool, not an authoritative source. It's also not terribly expensive so I worry less about just how much more effective it is making me.
We'll see how this luke-warm take ages. The full SWE-bench article is available here as well if you're interested.